
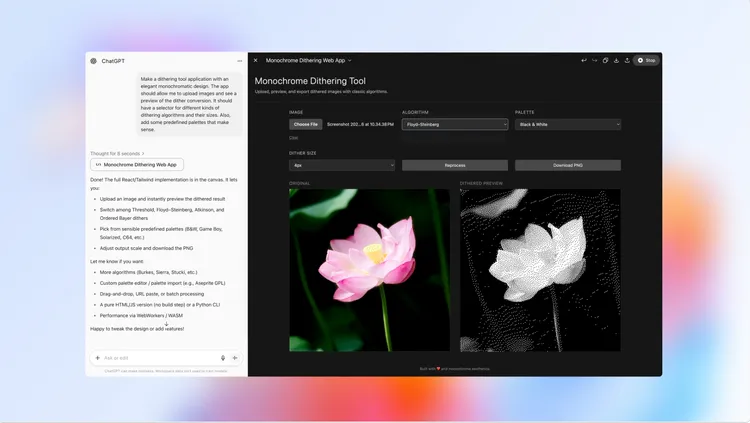
相較前代,GPT-5大幅降低「幻覺」錯誤率,指令遵循能力與實用性均有顯著提升,並針對ChatGPT 最常見的寫作、程式與健康三大應用進行強化。在程式領域,GPT-5展現更強的前端生成與大型專案除錯能力,甚至能依單一提示快速生成美觀、響應式的網站、應用與遊戲,且在排版與視覺美感上有更佳表現。
寫作方面,無論是結構曖昧的詩歌創作、自由詩流暢度,或是日常報告、信件撰寫,都能展現更高的文學層次與節奏感。健康應用上,GPT-5在官方HealthBench評測中刷新紀錄,能依使用者背景與地理位置提供更精準的資訊,並主動提醒潛在健康疑慮,但並不取代專業醫療人員。
在性能評測中,GPT-5在數學、軟體工程、多模態理解與健康問答等多項基準測試均創下新高,例如 AIME 2025 數學競賽達到94.6% 正確率(無工具輔助)、SWE-bench Verified 軟體工程測試達 74.9%(使用推理模式)、HealthBench Hard得分46.2%,遠超過GPT-4o與OpenAI o3。此外,在多語言程式編輯、圖像與影片理解、空間推理及科學圖表解析等領域,GPT-5也全面領先。
安全性方面,GPT-5導入全新的「安全完成(Safe Completions)」訓練方法,讓模型在符合安全界限的前提下盡可能提供有用資訊,並在雙重用途(dual-use)領域如病毒學問題上展現更細緻的應對能力,同時明確解釋拒答原因。官方指出,GPT-5在測試中將過度奉承(sycophancy)率從14.5%降至不足6%,減少過度迎合用戶的傾向,對話風格更自然。
OpenAI同步推出GPT-5 Pro,採用更長時間推理與並行計算,專為複雜高難度任務設計,在健康、科學、數學與程式領域均表現最佳,並在超過千題高價值推理測試中獲得專家 67.8% 偏好。
GPT-5現已成為ChatGPT預設模型,取代GPT-4o、o3、o4-mini、GPT-4.1與GPT-4.5,免費用戶、Plus、Pro、Team 與 Enterprise 均可使用,不同方案的差異在於使用量與是否能使用GPT-5 Pro。付費用戶還能透過Codex CLI進行程式開發;免費用戶在達到GPT-5使用上限後,將切換至GPT-5 mini版本以維持服務。
 點擊閱讀下一則新聞
點擊閱讀下一則新聞




